ROADMAP
Neuromorphic computing is a research and development field that is of increasing scientific and practical interest. Both academic and industrial labs (from large companies to start-ups) are active in the field. Neuromorphic computing could enable efficient real-time and low-power AI in such applications as:
- Artificial Intelligence on the edge
- Sensor processing
- Health
- Robotics
- Natural language processing
- Personal assistants
- Autonomous vehicles
- Smart manufacturing
- Computational neuroscience
Neuromorphic computing is an extremely ambitious multi-disciplinary effort ranging from neuro-biology and cognitive science to electrical engineering and computer science, to studies of new materials, devices, systems, and algorithms. Our first action for developing a Roadmap is to improve the definition of neuromorphic computing. Rather than having an inside/outside boundary, we see neuromorphic computing as a goal towards which different R&D directions converge. Each given technology can be placed somewhere on each axis between the digital computing technology that we know today and the futuristic brain-like computing that we envision as our goal.
These directions are discussed on the following page. The goal corresponds to features of the brain as a computing system, which we seek inspiration from. These directions structure the roadmap of neuromorphic computing as they are the guiding principles of the field.
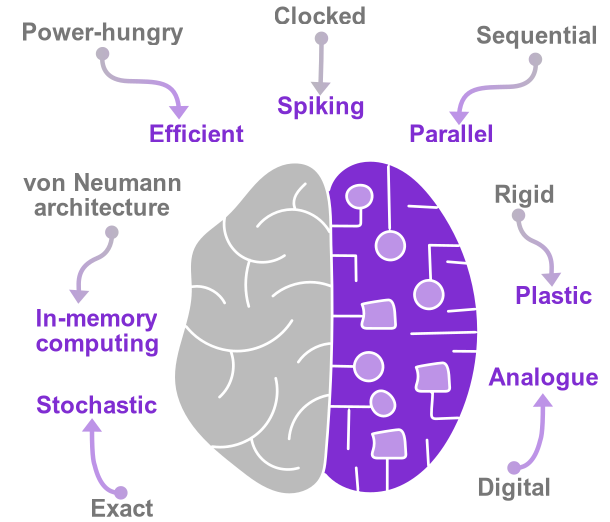
Brain-inspired computing
Simulation
vs
Hardware
Taking inspiration from the brain for computing is already present in machine learning and artificial intelligence through artificial neural network algorithms that can be implemented (simulated) on a conventional CPU. This abstract inspiration has already given rise to tremendous progress in image, video, audio and natural language processing, and to successful commercial applications.
However, in order to unlock significant gains in terms of performance and efficiency, a more ambitious step needs to be taken: to build a new kind of computers, inspired from the brain at the hardware level. This is the goal of neuromorphic computing. We seek not just simulate artificial neural networks, but to actually build them in hardware.
Power-hungry
vs
Efficient
Application-wise, one key motivation for neuromorphic computing is to achieve higher power efficiency than existing solutions. Artificial neural networks, when run on conventional hardware, consume a lot of energy, mainly because of the need to move around large amounts of data during computation. State-of-the-art GPUs consume several hundreds of Watts, which limits the deployment of neural networks on embedded systems. Even supercomputers consuming a Mega Watt cannot emulate the whole human brain, which limits our ability to improve our understanding of the brain through such simulations.
In comparison, the human brain only consumes on the order of 20 Watt. The energy efficiency of the brain is several hundreds of tera operations per second and per Watt, while existing solutions are limited to a few tera operations per second and per Watt. By building computers inspired from the brain at the hardware level, neuromorphic computing aims to bridge this energy efficiency gap.
von Neumann architecture
vs
In-memory computing
Conventional computers rely on the von Neumann architecture, where memory and computing are physically separated. In consequence, a large part of the energy consumption and delays are due to the transfer of information between memory and computing parts, a phenomenon often referred to as “von Neumann bottleneck”. In neural network algorithms, this issue is critical because huge numbers of parameters need to be stored and frequently addressed.
The brain is extremely different in this regard: memory and computing are completely intertwined. The neurons, which compute, are connected by synapses, which carry the memory. Neuromorphic computing aims at bringing memory and computing together to achieve “in-memory computing”. In-memory computing is being made possible through the development of emerging nanoscale memory devices. Various classes of such memories exist and will be discussed in this roadmap. Their common assets are that they are non-volatile, fast and low energy, can be read and written electrically and can be monolithically integrated into CMOS chips.
Rigid
vs
Plastic
Learning in the brain is made possible by its plasticity. The connections between neurons – the synapses – are not rigid but plastic, which means they can be modified. Learning, both in the brain and in artificial neural networks algorithms, corresponds to repetitive modification of the synapses until reaching a set of connections enabling the neural network to perform tasks accurately. In conventional computers, this is done by explicit modification of the memory banks storing the weights.
Neuromorphic computing aims at building systems where weights are self-modified through local rules. Here again, the role of non-volatile memories intertwined with computing circuits is critical. Their dynamics makes it possible to implement bio-inspired learning rules. For instance, memristors, analogue, or digital circuits can implement Spike Timing Dependent Plasticity, a bio-inspired local learning rule.
Clocked
vs
Spiking
Conventional computers are run by a clock which sets the pace of all circuits. This helps to synchronize and control all computing processing, but leads to unnecessary power consumption and rigid processing timing. There is no such clock in the brain.
Neurons emit and receive spikes in an asynchronous way. Neuromorphic engineering aims at building computers based on these principles. By having activity only when and where necessary, the energy consumption is more flexibly adjusted to the system’s needs.
Exact
vs
Stochastic
Conventional computers aim at very high precision, coding numbers in up to 64 bits floating point precision. This precision comes at a cost. The overhead of making high-precision representations robust is not justified in some cases – when represented values are in fact not that precise. Relaxing the constraints on the exactitude of components and computing steps that enable precise representations will decrease energy consumption.
The biological substance of the brain is noisy and neurons and synapses exhibit variability and stochasticity. Resilience to and even use of such imprecision is a key asset of biological neural networks. Obtaining accurate results with approximate computing components and steps is a goal of neuromorphic computing. This will be crucial to be able to use components in their analogue regime, where noise and variability are more significant.
Digital
vs
Analogue
Conventional computers rely on digital encoding: voltages in the processor at the steady state only take two values, which represent 0 and 1. Transient intermediary values do not represent anything. All numbers are coded in binary, as a string of 0 and 1. This leads to a reliable substrate for computation, but is costly energetically. In the brain, this is not the case.
The electrical potential at the membranes of neurons can take continuous values, and so can the synaptic weights. Reproducing such behavior with digital encoding takes large circuits. Thus, using directly an analogue encoding will improve efficiency. Neuromorphic computing aims at using components which intrinsic analogue behavior mimics the key functions of neurons and synapses. This can be achieved by CMOS transistors used in an analogue regime and by emerging technologies such as spintronic nanodevices or photonics. The key towards successful use of such technology is development of algorithms that can cope with inherent variability and noise in analogue circuits.
Sequential
vs
Parallel
Parallel computing is a much studied topic beyond the scope of neuromorphic computing. However, parallel computing in conventional computer architectures is quite limited. Approaching the parallelism of the brain will require drastic changes in computer architectures. Moreover, it will require low power components so that they can all function simultaneously. Indeed, in current processors, the whole chips cannot function simultaneously because of power budget.
One of the most impressive features of the human brain is its massive parallelism. Although each neuron computes at the millisecond scale (much slower than CMOS transistors which function below the nanosecond), the brain can perform 100 Tera Operations per second, orders of magnitude more than artificial neural networks on conventional computers. The key component of this parallelism is co-location of memory and computing, alleviating the von Neumann memory bottleneck, requiring sequential memory access.